Google 스프레드시트로 데이터를 가져오거나 수동으로 입력하는 경우 텍스트를 변경하거나 수정해야 하는 상황이 발생할 수 있습니다. 목록에 있는 Google 스프레드시트 텍스트 기능을 사용하여 시간을 절약할 수 있어요 여러 가지 사항을 한 번에 빠르게 변경할 수 있습니다.
숫자를 텍스트로 변환: TEXT
지정된 형식을 사용하여 숫자를 텍스트로 변환하는 간단한 방법으로 시작하는 것이 TEXT 함수입니다. 날짜, 시간, 백분율, 통화 또는 유사한 숫자에 사용할 수 있습니다.
수식 구문은 TEXT(숫자, 형식)입니다. 여기서 첫 번째 인수에 정확한 숫자나 셀 참조를 사용할 수 있습니다. 사용하려는 형식에 따라 Google 문서 편집기 도움말 페이지 을 방문하여 두 번째 인수에 대한 12개 이상의 옵션 목록을 확인할 수 있습니다.
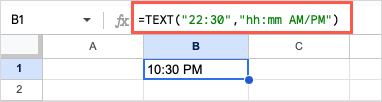
예를 들어 다음 공식을 사용하여 22시 30분을 AM 또는 PM을 포함한 12시간 형식과 텍스트 형식으로 지정하겠습니다.
=TEXT(“22:30”,”hh:mmAM/PM”)
또 다른 예로 A1 셀의 숫자 형식을 다음 수식을 사용하여 백분율 기호가 있는 텍스트로 지정하겠습니다.
=TEXT(A1,”0%”)

텍스트 결합: CONCATENATE
두 개의 텍스트 문자열을 결합하려면 CONCATENATE 함수를 사용하세요 하면 됩니다. 이름과 성, 도시와 주 또는 이와 유사한 항목을 하나의 셀로 결합하고 싶을 수 있습니다.
구문은 CONCATENATE(string1, string2,…)이며, 여기서 인수에 대한 텍스트 또는 셀 참조를 사용할 수 있습니다.
이 예에서는 다음 수식을 사용하여 셀 A1부터 D1까지의 텍스트를 단일 문자열로 결합합니다.
=연결(A1:D1)

단어 사이에 공백을 넣으려면 다음 공식을 사용하여 각 셀 참조 사이에 따옴표 안에 공백을 삽입하면 됩니다.
=연결(A1,” “,B1,” “,C1,” “,D1)

또 다른 예로, 다음 수식을 사용하여 '이름: '이라는 텍스트와 A1 셀의 텍스트를 결합하겠습니다.
=CONCATENATE(“이름: “,A1)

텍스트를 구분 기호로 결합: TEXTJOIN
TEXTJOIN 함수는 텍스트 결합을 위한 CONCATENATE와 유사합니다. 차이점은 구분 기호(구분 기호)를 사용할 수 있고 TEXTJOIN으로 배열을 결합할 수 있다는 것입니다..
구문은 TEXTJOIN(구분자, 비어 있음, 텍스트1, 텍스트2,…)입니다. 구분 기호인수의 경우 공백, 쉼표 또는 기타 구분 기호를 따옴표로 묶고 빈인수의 경우 True를 사용하여 빈 셀을 제외하거나 False를 사용하여 포함합니다.
예를 들어 A1부터 C2까지의 셀 범위에 있는 텍스트를 구분 기호로 공백을 사용하고 TRUE로 결합하여 빈 셀(A2)을 무시합니다. 공식은 다음과 같습니다.
=TEXTJOIN(" ",TRUE,A1:C2)

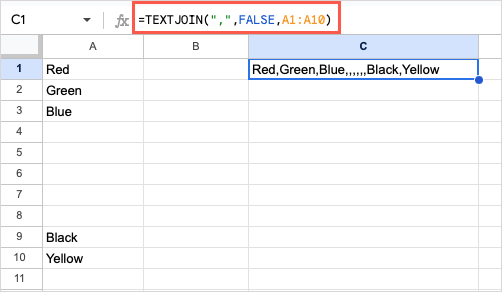
또 다른 예로, 셀 A1부터 A10까지의 텍스트를 쉼표로 구분 기호로 사용하고 FALSE를 사용하여 빈 셀(A4부터 A8)을 포함시켜 결과가 어떻게 나타나는지 확인하겠습니다. 공식은 다음과 같습니다.
=TEXTJOIN(“,”,FALSE,A1:A10)
팁: 숫자를 결합하려면 JOIN 함수 을 사용하면 됩니다.
별도의 텍스트: 분할
위와 반대로 텍스트를 결합하는 대신 텍스트를 분리하고 싶을 수도 있습니다. 이를 위해 SPLIT 기능을 사용할 수 있습니다.
구문은 SPLIT(텍스트,구분자,분할
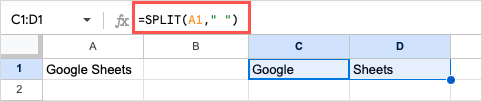
여기서 다음 수식을 사용하여 공백을 구분 기호로 사용하고 다른 인수의 기본값을 사용하여 셀 A1의 텍스트를 분할합니다.
=분할(A1,” “)
또 다른 예로, 't'를 구분 기호로 사용하여 셀 A1의 텍스트를 분할하겠습니다. 위의 공백 구분 기호를 제거하고 나머지 텍스트는 그대로 두는 것처럼 "t"가 제거됩니다. 공식은 다음과 같습니다.
=분할(A1,”t”)

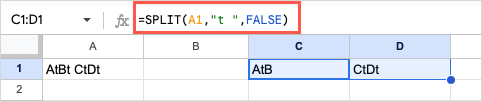
이제 FALSE를 split_by인수로 추가하면 이 수식은 "t[space]" 표시에서만 텍스트를 구분합니다.
=분할(A1,”t “,FALSE)
텍스트 비교: 정확
시트의 데이터를 비교하는 중입니까? EXACT 함수를 사용하면 두 개의 텍스트 문자열을 비교하고 일치 여부에 대한 간단한 True 또는 False 결과를 얻을 수 있습니다..
구문은 EXACT(text1, text2)이며 인수에 대해 텍스트 또는 셀 참조를 사용할 수 있습니다.
예를 들어 셀 A1과 B1의 두 텍스트 문자열을 다음 수식으로 비교하겠습니다.
=EXACT(A1,B1)

또 다른 예로 다음 공식을 사용하여 A1 셀의 텍스트를 'Google'과 비교하겠습니다.
=EXACT(A1,”Google”)

텍스트 변경: 교체 및 대체
Google 스프레드시트의 찾기 및 바꾸기 기능 를 사용할 수 있지만 기능에서 허용하는 것보다 더 구체적이어야 할 수도 있습니다. 예를 들어, 특정 지점의 문자를 변경하거나 문자열에서 텍스트의 특정 인스턴스만 변경하고 싶을 수 있습니다. 이 경우 REPLACE 또는 SUBSTITUTE를 사용할 수 있습니다.
비슷하지만 각 기능은 약간씩 다르게 작동하므로 필요에 가장 적합한 것을 사용할 수 있습니다.
각 구문은 REPLACE(text, position, length, new)및 SUBSTITUTE(text,search_for, replacement_with입니다. , 발생). 몇 가지 예와 인수 사용 방법을 살펴보겠습니다.
교체
여기에서는 'William H Brown'을 'Bill Brown'으로 바꾸려고 하므로 REPLACE 함수와 다음 공식을 사용하겠습니다.
=REPLACE(A1,1,9,”청구서”)
수식을 분석해 보면 A1은 텍스트가 있는 셀이고, 1은 바꿀 시작 위치, 9는 바꿀 문자 수, Bill은 바꿀 텍스트입니다.
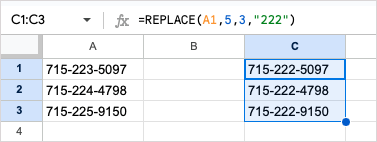
또 다른 예로, 전화번호가 텍스트로 저장되어 있고 각 번호의 접두사를 변경해야 합니다. 각 접두사가 다르기 때문에 REPLACE를 사용하여 대체할 문자의 위치와 수를 지정할 수 있습니다. 공식은 다음과 같습니다.
=REPLACE(A1,5,3,”222″)

팁: 한 열의 여러 셀을 변경하려면 아래와 같이 수식을 아래로 끌어 다음 행에 적용하면 됩니다.
대체
SUBSTITUTE 함수의 예를 들어, "new york"를 "New York"으로 바꾸고 occurrence인수를 추가하여 문자열의 첫 번째 인스턴스만 변경하도록 하겠습니다. 공식은 다음과 같습니다.
=SUBSTITUTE(A1,”뉴욕”,”뉴욕”,1)
이 수식을 분석하면 A1에 텍스트가 포함되고, 'new york'은 우리가 검색하는 텍스트이고, 'New York'은 대체 텍스트이고, 1은 텍스트가 처음 나타나는 텍스트입니다..

위 수식에서 occurrence인수를 제거하면 함수는 여기에서 볼 수 있듯이 기본적으로 두 인스턴스를 모두 'New York'으로 변경합니다.
=SUBSTITUTE(A1,”뉴욕”,”뉴욕”)

변경 대소문자: PROPER, UPPER, LOWER
데이터 입력 중에 다른 소스에서 데이터 가져오기 를 입력하거나 잘못 입력하면 대소문자가 일치하지 않을 수 있습니다. PROPER, UPPER, LOWER 기능을 사용하면 빠르게 수정할 수 있습니다.
각 구문은 PROPER(text), UPPER(text)및 LOWER(text)와 같이 간단합니다. 셀 참조 또는 인수에 대한 텍스트입니다.
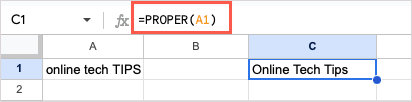
텍스트 문자열에서 각 단어의 첫 글자를 대문자로 표시하려면 PROPER 함수와 다음 공식을 사용할 수 있습니다.
=PROPER(A1)
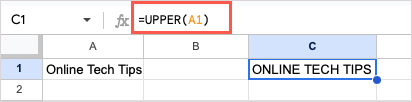
문자를 모두 대문자로 변경하려면 UPPER 함수와 다음 공식을 사용하세요.
=UPPER(A1)
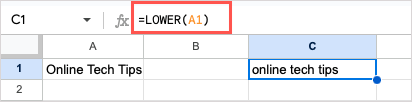
문자를 모두 소문자로 변경하려면 LOWER 함수와 다음 공식을 사용하세요.
=LOWER(A1)
다음과 같이 따옴표 안에 세 가지 함수 모두에 대한 정확한 텍스트를 입력할 수도 있습니다.
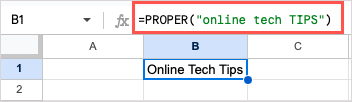
=PROPER(“online tech TIPS”)
텍스트 문자열의 일부 얻기: 왼쪽, 오른쪽, 중앙
텍스트 문자열의 일부를 추출해야 할 수도 있습니다. 데이터가 다른 데이터와 혼합되어 있거나 특정 항목에 문자열의 일부를 사용하려고 할 수 있습니다. LEFT, RIGHT, MID 기능을 사용하여 필요한 부분을 얻을 수 있습니다.
각각의 구문은 LEFT(string, num_characters), RIGHT(string, num_characters)및 MID(string)입니다. , 시작, 길이). 셀 참조나 텍스트를 각각의 string인수로 사용할 수 있습니다.
LEFT 함수의 예를 들어 다음 공식을 사용하여 A1 셀의 텍스트를 사용하여 왼쪽에서 처음 세 문자를 추출합니다.
=LEFT(A1,3)

RIGHT 함수의 예를 들어 다음 공식을 사용하여 동일한 셀을 사용하여 오른쪽에서 처음 4자를 추출합니다.
=RIGHT(A1,4)

MID 함수의 예를 들어 동일한 셀의 텍스트에서 'Jane'이라는 이름을 추출하겠습니다.
=MID(A1,6,4)
 .
.
이 MID 예에서 start인수에 6을 사용하면 왼쪽에서 6번째 문자가 선택됩니다. 공백과 구두점을 포함한 모든 문자가 중요하다는 점을 기억하세요. 그런 다음 length인수에 4를 사용하면 4개의 문자가 선택됩니다.
텍스트 문자열 길이 가져오기: LEN 및 LENB
데이터를 복사하여 붙여넣거나 다른 곳에서 사용하기 위해 내보내는 등 데이터에 특정한 작업을 수행하려는 경우 문자 수에 주의해야 할 수 있습니다. LEN을 사용하면 텍스트 문자열의 문자 수를 얻을 수 있고, LENB를 사용하면 바이트 수를 얻을 수 있습니다.
각 구문은 LEN(string)및 LENB(string)입니다. 여기서도 셀 참조나 텍스트를 사용할 수 있습니다. 인수로 사용하세요.
여기서 다음 공식을 사용하여 셀 A1에 있는 텍스트의 문자 수를 구합니다.
=LEN(A1)
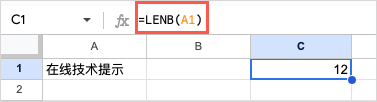
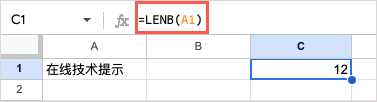
이 공식을 사용하면 A1 셀에 있는 텍스트의 문자 수를 바이트 단위로 얻을 수 있습니다.
=LENB(A1)
추가 공백 제거: TRIM
데이터의 앞, 뒤 또는 기타 추가 공백을 정리해야 하는 경우 TRIM 기능을 사용할 수 있습니다.
구문은 TRIM(text)이며, 인수로 셀 참조나 텍스트를 사용할 수 있습니다.
여기서 다음 수식을 사용하여 A1 셀의 텍스트 문자열에서 공백을 제거합니다.
=TRIM(A1)

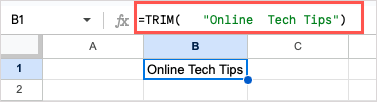
다음으로 다음 공식을 사용하여 특정 텍스트 '온라인 기술 팁'에서 추가 공백을 제거하겠습니다.
=TRIM( “온라인 기술 팁”)
Google 스프레드시트 기능으로 텍스트 처리
Google 스프레드시트는 텍스트 작업을 위한 다양한 기능을 제공합니다. 텍스트 줄 바꿈, 형식 변경, 하이퍼링크 등을 수행할 수 있습니다. 그러나 데이터세트가 길 경우 Google Sheets 텍스트 기능을 사용하면 텍스트 변경사항을 더 빠르고 효율적으로 처리하는 데 도움이 될 수 있습니다. 한두 번 시도해 보시겠습니까?
관련 튜토리얼은 배열에 Google 스프레드시트 수식을 사용하는 방법 을 참조하세요..