오프라인에서 볼 수 있도록 웹 페이지 또는 웹 사이트를 저장해야합니까? 오랜 시간 동안 오프라인 상태가 되겠지만 즐겨 찾는 웹 사이트를 탐색 할 수 있기를 원하십니까? Firefox를 사용하는 경우 문제를 해결할 수있는 Firefox 추가 기능이 하나 있습니다.
스크랩북 은 Firefox 확장 기능으로 당신은 웹 페이지를 저장하고 관리하기 쉬운 방식으로 그들을 구성 할 수 있습니다. 이 부가 기능에 대한 정말 멋진 점은 매우 가볍고 빠르며 정확하게 웹 페이지의 로컬 복사본을 거의 완벽하게 캐시하고 여러 언어를 지원한다는 것입니다. 나는 많은 그래픽과 멋진 CSS 스타일을 가진 여러 웹 페이지에서 그것을 테스트했고, 오프라인 버전이 온라인 버전과 완전히 똑같은 것을 보아서 놀랍도록 기뻤습니다.
스크랩북 설치
이 글을 쓰고있는 시점에 v33이라는 최신 버전의 Firefox를 실행하고 있다면 ScrapBook을 올바르게 사용할 수 있도록 일부 설정을 조정해야합니다. 기본적으로 스크랩북 아이콘은 아무 데나 나타나지 않으므로 웹 페이지를 마우스 오른쪽 버튼으로 클릭하면 사용할 수있는 유일한 방법입니다. 사용자 정의를 선택하여 툴바 또는 메뉴에 버튼을 추가하십시오.
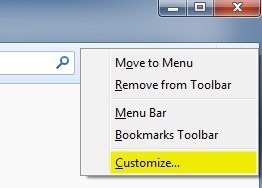
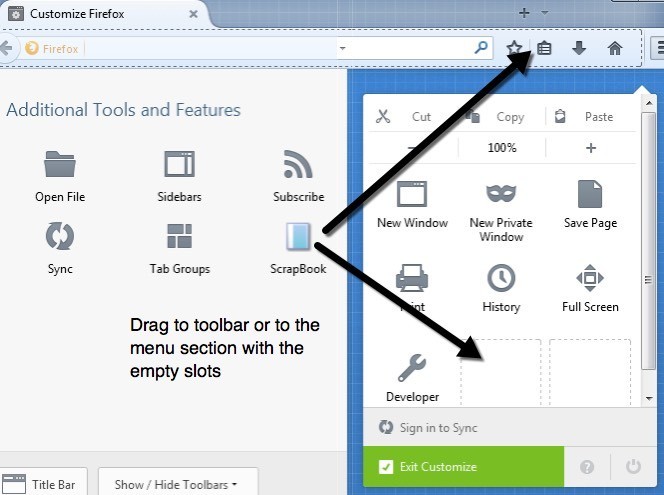
사용자 화 화면에서 왼쪽에 ScrapBook 아이콘이 표시됩니다. 어서 도구 모음의 상단이나 메뉴로 드래그하십시오. 그런 다음 Exit Customize버튼을 클릭하십시오.
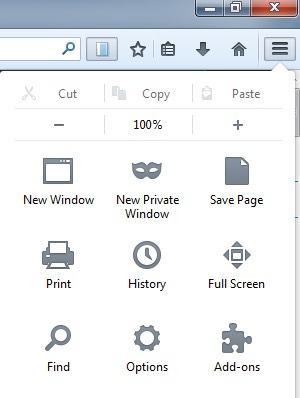
스크랩북을 사용하여 웹 사이트를 저장하기 전에 추가 기능의 설정을 변경하고자 할 수 있습니다. 오른쪽 상단에있는 메뉴 버튼 (세 개의 수평선)을 클릭 한 다음 부가 기능을 클릭하면됩니다.
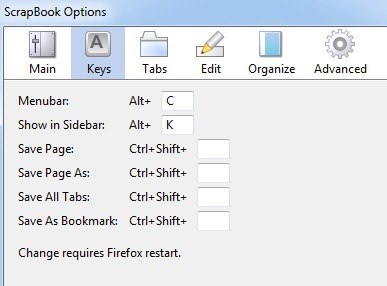
이제 확장 프로그램을 클릭 한 다음 스크랩북 부가 기능 옆에있는 옵션버튼을 클릭하십시오.
5 키보드 단축키, 데이터가 저장되는 위치 및 기타 사소한 설정을 변경할 수 있습니다.
스크랩북을 사용하여 사이트를 다운로드하십시오.
이제 프로그램을 실제로 사용하는 방법에 대해 자세히 알아 보겠습니다. 먼저 웹 페이지를 다운로드 할 웹 사이트를로드하십시오. 다운로드를 시작하는 가장 쉬운 방법은 페이지의 아무 곳이나 마우스 오른쪽 버튼으로 클릭하고 메뉴 하단에 페이지 저장또는 다른 이름으로 페이지 저장을 선택하는 것입니다. 이 두 옵션은 스크랩북으로 추가됩니다.
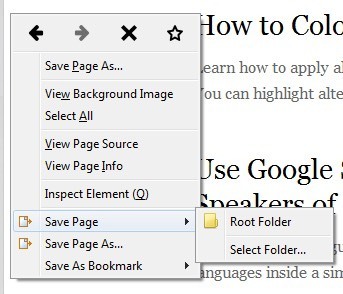
페이지 저장을 사용하면 폴더를 선택한 다음 현재 페이지 만 자동으로 저장할 수 있습니다. 평상시에 더 많은 옵션을 원한다면 다른 이름으로 페이지 저장 옵션을 클릭하십시오. 다양한 옵션을 선택하고 선택할 수있는 또 다른 대화 상자가 나타납니다.
중요한 섹션은 옵션, 링크 된 파일 다운로드섹션, 인 섹션-depth Save옵션을 사용하십시오. 기본적으로 ScrapBook은 이미지와 스타일을 다운로드하지만 웹 사이트에서 올바르게 작동해야하는 경우 JavaScript를 추가 할 수 있습니다.링크 된 파일 다운로드 섹션에서는 링크 된 이미지를 다운로드하지만 다운로드 할 수도 있습니다. 파일을 보관하거나 다운로드 할 파일의 정확한 유형을 지정하십시오. 이는 특정 유형의 파일 (워드 문서, PDF 등)에 대한 링크가 많이 있고 관련 파일을 모두 빠르게 다운로드하려는 웹 사이트에있는 경우 매우 유용한 옵션입니다.
마지막으로 심층 저장옵션은 웹 사이트의 더 많은 부분을 다운로드하는 방법입니다. 기본적으로 0으로 설정되어 사이트의 다른 페이지 또는 다른 링크에 대한 링크를 따르지 않습니다. 하나를 선택하면 현재 페이지와 해당 페이지에서 링크 된 모든 것을 다운로드합니다. 현재 페이지, 첫 번째 연결된 페이지 및 첫 번째 연결된 페이지의 모든 링크에서 2의 깊이가 다운로드됩니다.
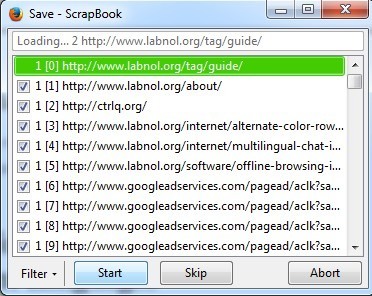
새 창이 열리고 페이지가 다운로드되기 시작합니다. 즉시 일시 중지버튼을 눌러 그 이유를 알려주고 싶습니다. ScrapBook을 실행 시키면 다른 사이트 또는 광고 네트워크에 링크 될 수있는 소스 코드의 모든 내용을 포함하여 페이지의 모든 것을 다운로드하기 시작합니다. 위 이미지 (메인 사이트 (labnol.org) 외부)에서 볼 수 있듯이 googleadservices.com의 광고와 ctrlq.org의 광고를 다운로드합니다.
광고를 실제로 게재 하시겠습니까? 사이트를 오프라인에서 탐색하는 동안 사이트에 있습니까? 이렇게하면 많은 시간과 대역폭이 낭비되므로 가장 좋은 방법은 일시 중지를 누른 다음 필터버튼을 클릭하는 것입니다.
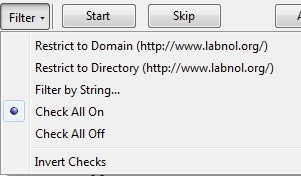
도메인으로 제한및 디렉토리로 제한중에서 가장 좋은 옵션은 두 가지입니다. 일반적으로 이들은 동일하지만 특정 사이트에서는 서로 다릅니다. 원하는 페이지를 정확히 알고 있다면 문자열로 필터링하고 자신의 URL을 입력 할 수도 있습니다. 이 옵션은 다른 모든 정크를 없애고 소셜 미디어 사이트, 광고 네트워크 등에서보다 실제 웹 사이트의 콘텐츠 만 다운로드하기 때문에 멋진 옵션입니다.
계속 >시작을 클릭하면 페이지가 다운로드되기 시작합니다. 다운로드 시간은 인터넷 연결 속도와 다운로드하는 웹 사이트의 양에 따라 다릅니다. 부가 기능은 대부분의 사이트에서 잘 작동하며 내가 만난 유일한 문제는 일부 사이트에서 자신의 콘텐츠에 연결하는 데 사용하는 URL이 절대 URL이라는 것입니다.
절대 URL 문제 오프라인에서 Firefox에서 색인 페이지를 열고 링크를 클릭하려고하면 로컬 캐시가 아닌 실제 웹 사이트에서로드하려고 시도합니다. 이 경우 수동으로 다운로드 디렉토리를 열고 페이지를 열어야합니다. 그것은 고통이며, 소수의 사이트에서만 발생했습니다. 그러나 발생합니다. 툴바에서 스크랩북 버튼을 클릭 한 다음 사이트를 마우스 오른쪽 버튼으로 클릭하고 도구- 파일 표시를 선택하여 다운로드 폴더를 볼 수 있습니다.
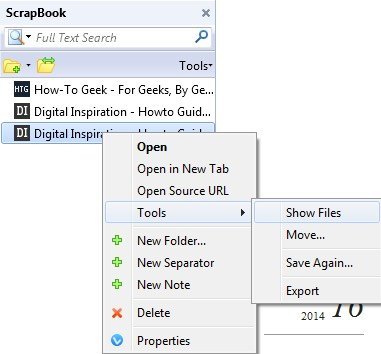
탐색기에서 유형으로 정렬 한 다음 HTML 문서라는 파일로 스크롤합니다.콘텐츠 페이지는 일반적으로 index_00x 파일이 아닌 default_00x 파일입니다.
컴퓨터에 웹 페이지를 다운로드하려면 라는 소프트웨어를 체크 아웃하면 나중에 오프라인에서 탐색 할 수 있도록 전체 웹 사이트를 자동으로 다운로드합니다. 그러나 WinHTTrack은 충분한 공간을 차지하므로 하드 드라이브에 충분한 여유 공간이 있는지 확인하십시오.
두 프로그램 모두 전체 웹 사이트를 다운로드하거나 단일 웹 페이지를 다운로드 할 때 적합합니다. 실제로 WordPress와 같은 CMS 소프트웨어에 의해 생성되는 수많은 링크로 인해 전체 웹 사이트를 다운로드하는 것은 거의 불가능합니다. 질문이 있으면 의견을 게시하십시오. 즐기십시오!